得獎同學:華方綾
論文題目:基於因素分析與變數相對重要性之變數選擇方式及其應用
指導教授:陳正剛博士
論文主要貢獻:
本研究主要貢獻在統計領域高維度資料的變數選擇,方法上引入新的概念與架構,使得最終的計算速度皆較改良方法前之學者提出的方法快、解釋力增加,且最終透過模擬案例與基因表現資料預測之結果較主流之變數選擇方法佳。
論文摘要:
高維度小樣本資料是資料探勘領域中的一個挑戰,這種類型的資料在生物資訊領域中尤為常見,比如說基因表現微陣列資料記載了人體成千上萬個基因,而樣本數卻只有幾百。要如何從眾多的基因中找出關鍵基因以預測產生疾病的可能性是一大課題。以統計領域中迴歸分析方法的觀點來看,這是變數選擇的問題,至今有諸多學者提出不同方法,而其中的癥結點是該如何處理變數的「共線性」問題以及變數的「組合」解釋力。
針對共線性問題,J.W.Johnson(2000)利用R.M.Johnson(1966)所提出的「最佳近似正交轉換方法」轉換自變數(X)得到正交的中介變數(𝐙),再透過中介變數 𝐙 計算變數相對權重(Relative Weight),然而該方法僅適用於樣本數(𝑛)大於變數數量(𝑝)且變數間無線性相關,也就是 X 為滿秩(full-rank)之情況,故Shen and Chen(2020)延伸 J.W.Johnson 的相對權重 (Relative Weight),提出「普適型相對重要性」(Comprehensive Relative Importance)計算方法,使得任何 𝑛 及 𝑝 的數值型資料皆可適用,然而該方法在 𝑝 非常大且 𝑝 > > 𝑛 時,所需之矩陣計算量也隨之過大。
本研究的目的為建立在以上學者針對相對重要性議題所提出之方法上,針對 𝑝 非常大的問題,提供一個在因素分析的框架上計算變數相對重要性的方法。假設在高維度問題中自變數量 𝑝 很大,但 X 矩陣的 rank 只有 𝑟 ,本研究首先利用因素分析中的因素萃取及因素變異最大化(Varimax) 旋轉獲得的 𝑟 個因素,取代原有相對重要性計算中的「最佳近似正交轉換」的 𝑝 個中介變數,再計算得到變數相對重要性後排序選取重要變數進入迴歸模型。本研究同時也嘗試創新因素萃取方法,增加考量對應變數的解釋力,也就是計算自變數與應變數之間的相關係數,將其排序並選擇前 𝑟(𝑟 < < 𝑝)個大的變數,接著透過最佳近似正交轉換得到 𝑟 個垂直中介變數 𝐙,再對 𝑟 個 𝐙 進行 Varimax 旋轉以得到『𝑟 個因素」,之後再計算得到變數相對重要性。
原本 Shen and Chen (2020) 都是在 𝑛 維空間的 𝑝 維子空間操作,但本研究方法降到 𝑟 維空間計算變數相對重要性,由此帶來的好處是計算量下降。另外,Shen and Chen(2020)並未真正解決共線性問題,也就是自變數在計算上是透過不垂直的中介變數解釋應變數的變異,但本研究方法確保中介變數互相垂直,因此得以合理使用中介變數分配相對重要性到原始自變數上,由此亦更具解釋性。
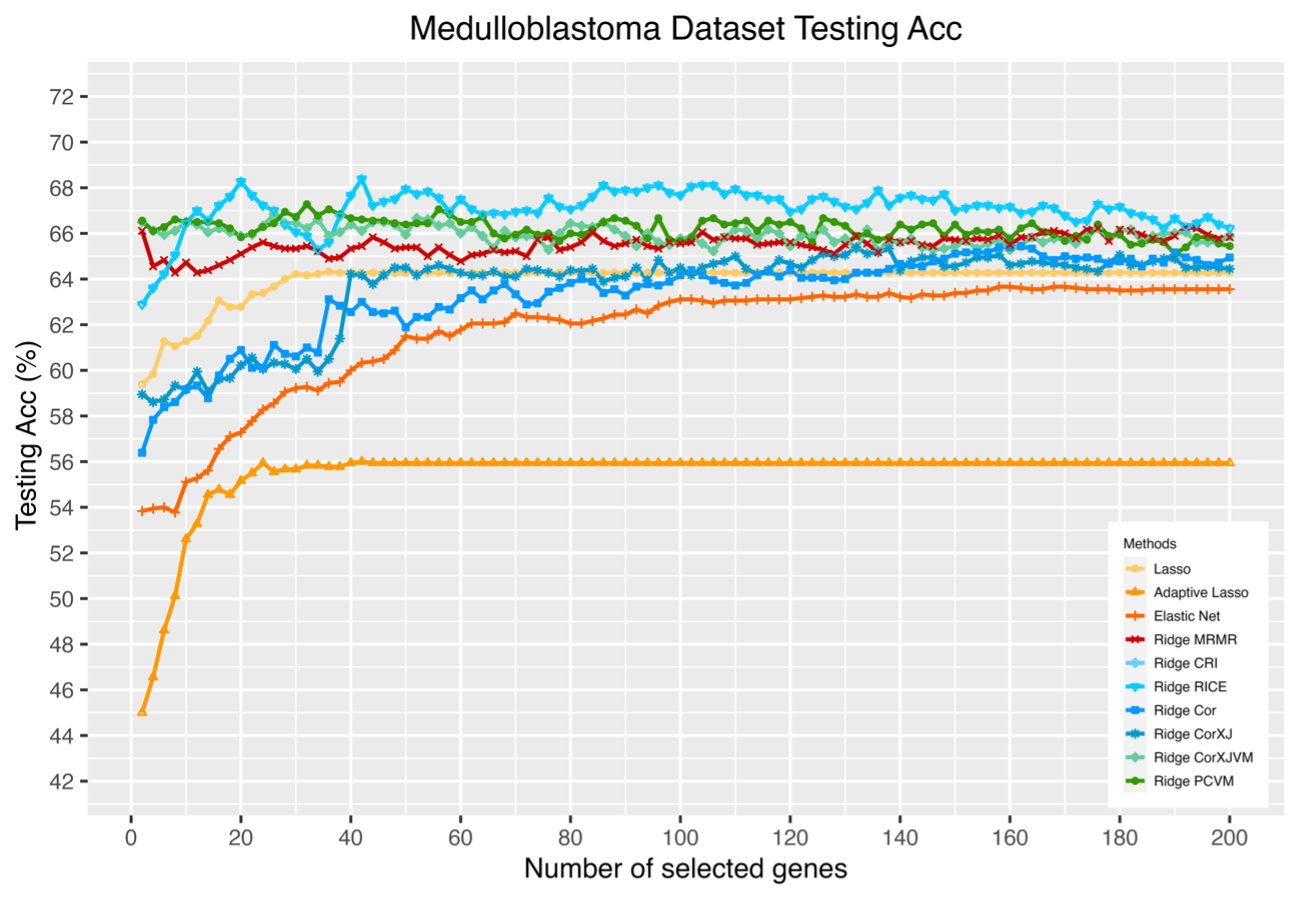
本文使用模擬案例以及基因表現資料進行方法驗證。從模擬案例中可以發現本研究方法可以找出實驗設定的垂直因素,在高度共線性的情形,其變數選擇表現及計算效率也比 Shen and Chen (2020) 變數相對重要性方法更好,達到利用因素分析計算變數相對重要性的目標。在基因表現資料的建模預測中,本研究方法的預測結果大部分較傳統的變數選擇方法好,且能夠在某些案例中與 Shen and Chen(2020) 的方法表現相當。
關鍵字:變數選擇、因素分析、相對重要性、基因表現