科技部透過補助優秀年輕學者奠定研究基礎,培育我國下世代科研人才,促使具潛力之年輕優秀學者於研究職涯初期能專注於新興議題,培養未來工程及應用科學領域之傑出研究人才。研究計畫為「發展分類感知之特徵萃取與自適應資料增強技術以分析類別比例失衡資料」。
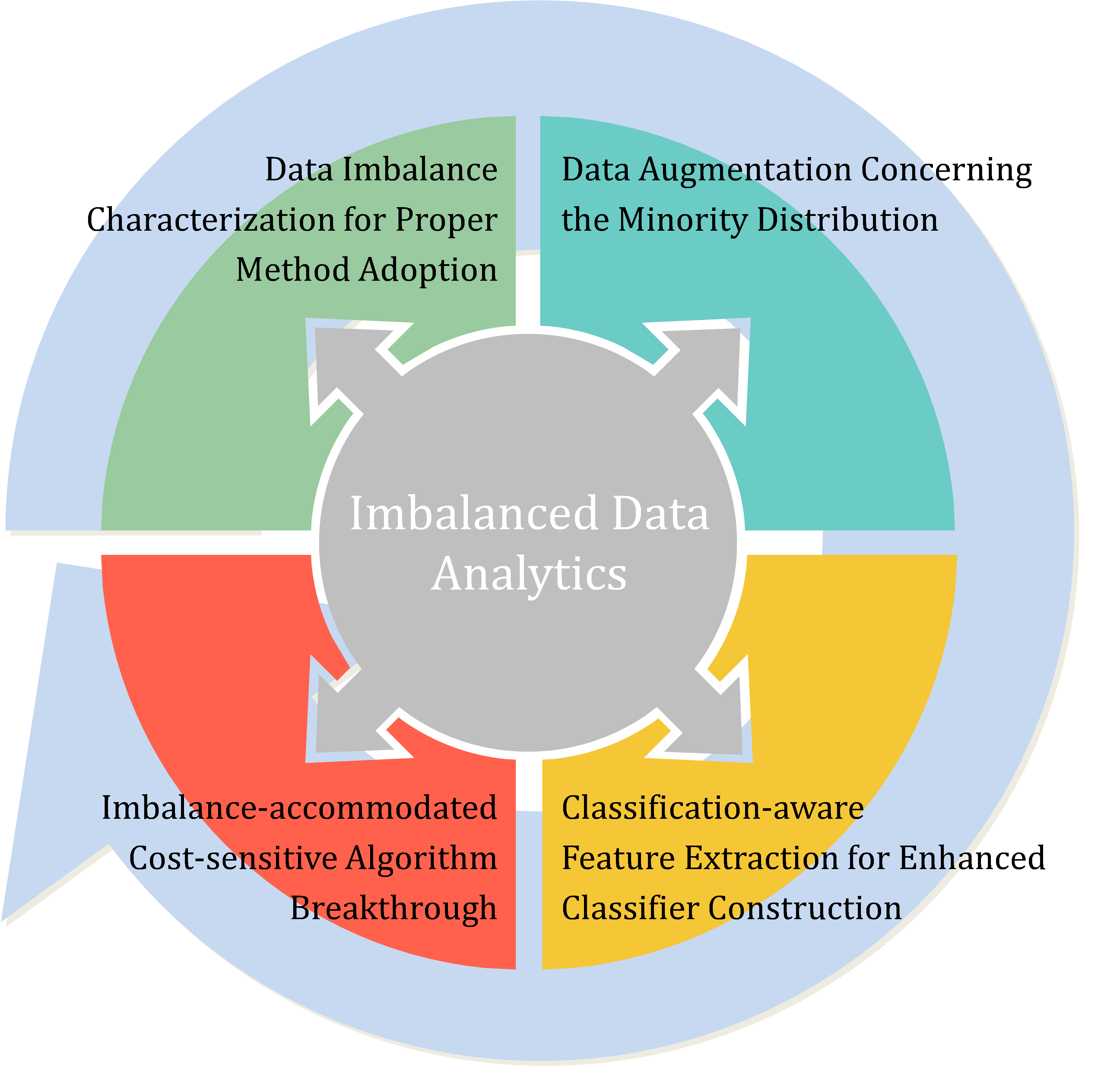
類別比例失衡資料分析一直是巨大的挑戰,特別在資料收集可能偏誤、比例失衡時,資料量多與模型有效並不能劃上等號。當弱勢類別樣本數遠低於強勢類別樣本數時,此失衡狀態將導致模型失效。尤其是以準確度為分類目標的模型,很容易被訓練成一味判斷強勢類別的分類器,然而弱勢類別樣本往往才是最需要被檢測和控制的事件,例如信用卡交易欺詐和瑕疵品。傳統方法多從資料預處理生成和代價敏感演算法兩個角度來切入,且缺乏系統化的解決框架。在本計畫中,類別比例失衡資料分析將分為四步驟:1. 評估失衡度;2. 發展自適應資料增強方法;3. 萃取分類感知特徵;4. 整合失衡度的代價敏感集成學習。在資料預處理前,應先評估弱勢類別特性,弱勢樣本雖同屬一類,但由於是罕發事件,彼此特性不盡相同,應根據個別弱勢樣本的失衡度,開發使用適配的資料增強技術。當類別趨於平衡,可透過同時訓練降維模型和分類器,萃取出分類感知特徵,該特徵不僅能夠重現原始資料,且能有效地進行分類。此外,為防止特徵工程失去可釋性,將以XAI技術確保特徵與原始物理意義的關聯。最後,代價敏感集成學習演算法須整合失衡度作為分類模型。四步驟構成一循環迴路,成為分析類別比例失衡資料集的系統性框架。